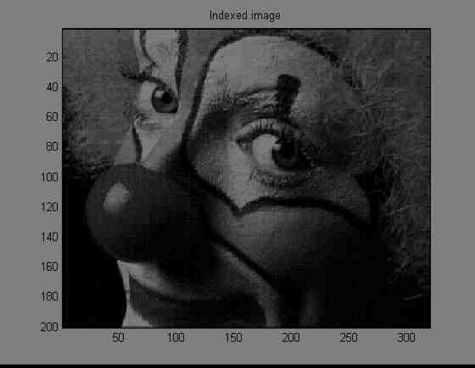
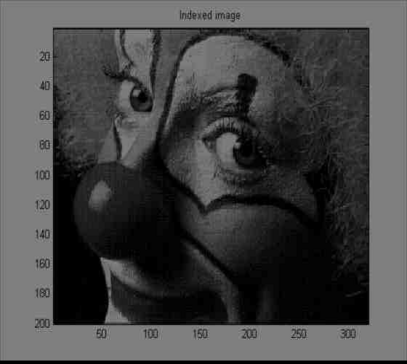
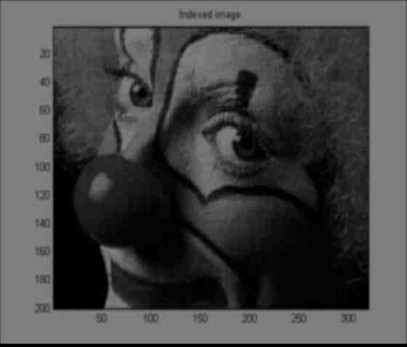
JPEG BlockingI previously talked about audio compression. But I have also worked with image compression. Surprise! My brief experience with this was in a class. All compression is fundamentally the same. Allocate the least bits to the most frequently represented symbols. If all symbols are equally represented, then the signal is at maximum uncertainty or entropy, which is almost the same thing. In this case, your signal would be white noise, and it can't be compressed. One technique in image compression is to break the image up into 8x8 blocks, apply the DCT, quantize, and compress. This is essentially how jpeg compression works. One reason the DCT is chosen as the transform is that it has good energy compaction properties. Most of the energy in the signal will be concentrated into the first few coefficients. And the human eye is supposed to be somewhat insensitive to the higher frequencies. Thus you can quantize them quite heavily. However, there may be other reasons for using the DCT as well. An unfortunate side effect of breaking the image up into 8x8 blocks is that the blocking is visible in the decompressed image. In a highly compressed image, it is very noticeable. There are various techniques for decreasing the blocking effect. They range from very simple filtering and averaging to more complex ideas such as projection onto convex sets. (If you have the time to learn optimization theory, then I say go for it.) I had the idea that averaging spatial domain, decompressed images, where the blocking was shifted, might lead to better results. But this requires saving multiple copies of the compressed image, which isn't realistic. After doing some research, I found a similar idea that doesn't require saving multiple compressed images. Not realizing this is a post-processing only technique (most are), I implemented this as averaging in the DCT domain. That's OK. I still got some interesting results. The first image below is the decompressed image without any additional processing. Only the DCT and quantization steps were performed. The second one is the same except eight extra copies of the image were averaged in the DCT domain. The extra copies were shifted at most one pixel horizontally, vertically, or both. And they were weight less than the main copy. There is a hint of blur in the decompressed image due to the shifting and averaging. Although the blocking doesn't appear any different on the clown between the first and second images, there seems to be less blocking around the numbers and letters (by my inspection). In the last image, 48 extra weighted images were averaged. The blur at this point is very bad. And it appears to have actually increased blocking of the hair. What is interesting about trying to deblock an image this way is that it's a preprocessing step. No post-processing is required. This is desirable if possible because an image usually only needs to be compressed once, but it may be decompressed frequently. Due to the high complexity of some post-processing algorithms, frequent decompression may be undesirable. Some more work remains to be done. I didn't experiment much with the weights. I also quantized twice -- after the DCT and after averaging. You might get better results by quantizing only at the end. It would also be useful to compare the second image to a post-processed, low pass filtered image. I couldn't do this without writing my own conv2 for octave. Getting OctaveYou will need to install octave. Since the Unix culture believes strongly in code reuse, you will also need gnuplot and imagemagick. Take care of the first two with emerge octave and the last with emerge imagemagick. If you don't have Gentoo, well, have fun! You will also nee , , and . Copy the first two into /usr/share/octave/2.1.69/m/signal and the last into /usr/shae/octave/2.1.69/m/image. Your directories might be a bit different. You will also need matlab or octave mode for emacs. I suggest using matlab mode; it's much more complete. The only trouble is that octave lets you use '#' and '"' for comments and strings respectively. But these are invalid in matlab syntax, and it will confuse matlab mode. So you might want to avoid them, or change them to '%' and '''. Resources |
{kind=link}
{kind=link}
{kind=link}